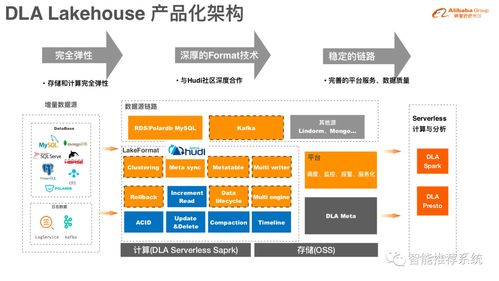
数据湖存储格式Hudi 核心原理与实践指南
随着大数据技术的快速发展,数据湖已成为企业数据架构的核心组件。在众多数据湖存储格式中,Apache Hudi(Hadoop Upserts Deletes and Incrementals)以其出色的增量数据处理和存储管理能力脱颖而出,为数据处理和存储服务带来了革命性的变化。本文将深入探讨Hudi的核心原理,并结合实践案例,阐述其在现代数据处理与存储服务中的应用。
Hudi的核心原理
Hudi的核心设计理念在于解决传统数据湖存储(如Parquet、ORC)在更新、删除和增量处理上的局限性。其原理主要体现在以下几个方面:
- 事务性支持与时间旅行:Hudi通过引入事务管理层,为数据湖提供了ACID(原子性、一致性、隔离性、持久性)事务支持。它将每一次数据操作(写入、更新、删除)都记录为一个提交(Commit),并维护一个时间线(Timeline)。这使得用户可以基于时间点查询数据的历史快照,实现“时间旅行”功能,为数据回溯、审计和增量ETL提供了强大支持。
- 高效的更新与删除:Hudi通过两种主要的表类型来处理数据的变更:
- Copy-on-Write(写时复制):在数据写入时直接创建新的数据文件版本。对于更新操作,它会找到包含该记录的文件,将其与未变更的记录合并,写入一个新文件。这种方式读性能好(因为总是读取最新的优化文件),但写操作开销较大。
- Merge-on-Read(读时合并):将更新和删除操作记录在增量日志文件中。查询时,系统将基础数据文件与增量日志实时合并,提供最新视图。这种方式写延迟低,适合频繁更新的场景,但读操作需要额外的合并开销。
- 索引机制:Hudi内置了高效的索引系统(如布隆过滤器索引、HBase索引等),能够快速定位一条记录所在的数据文件,从而避免在更新或删除时进行全表扫描,极大地提升了增量处理的性能。
- 自动文件管理:Hudi可以自动管理小文件合并、清理过期快照等存储优化任务,帮助用户维护数据湖的健康状态,减少存储成本并提升查询效率。
Hudi在数据处理与存储服务中的实践
Hudi的原理为其在数据处理流水线和存储服务中的实践应用奠定了坚实基础。以下是几个关键的实践场景:
1. 近实时数据入湖与增量ETL:
传统批处理将全量数据周期性覆写,效率低下且资源浪费。利用Hudi,可以将Kafka等流式数据源的数据近实时地以增量方式写入数据湖。下游的ETL作业可以仅消费自上次处理以来变化的数据(通过Hudi的增量查询),实现分钟级甚至秒级的低延迟数据处理管道,显著提升数据处理效率和时效性。
2. 构建CDC(变更数据捕获)流水线:
从业务数据库(如MySQL)通过CDC工具(如Debezium)捕获的INSERT、UPDATE、DELETE操作,可以直接写入Hudi表。Hudi能够精确应用这些变更,在数据湖中维护与源库一致的数据副本。这为构建企业级数据仓库、数据中台提供了实时、一致的维度表和数据基础。
3. 统一批流存储与服务层:
Hudi表可以同时作为批处理(Spark、Hive)和流处理(Flink、Spark Streaming)作业的源与目标。这种“流批一体”的存储层,简化了架构,避免了Lambda架构中维护两套代码和存储的复杂性。查询引擎(如Presto、Trino、Spark SQL)可以通过Hudi connector直接查询最新的或历史某个时刻的数据,为数据服务层(如数据API、即席查询)提供统一、高效的数据访问接口。
4. 数据治理与生命周期管理:
利用Hudi的时间旅行功能,可以轻松实现数据版本回溯、错误数据修复和合规性审计。结合其自动清理策略,可以定义保留多少历史快照,自动清理旧数据,在满足合规要求的同时优化存储成本。
实践建议与挑战
在实践中,成功应用Hudi需要注意以下几点:
- 表类型选择:根据读写模式选择Copy-on-Write(偏重查询)或Merge-on-Read(偏重频繁更新)。
- 索引配置:根据数据规模和键的分布选择合适的索引类型,以平衡写入性能和查找效率。
- 分区策略:合理的数据分区能极大提升增量处理和数据修剪的效率。
- 与现有生态集成:确保Hudi与公司现有的计算引擎(Spark/Flink)、资源调度器(YARN/K8s)和元数据管理系统良好兼容。
挑战主要在于运维复杂度有所增加,需要团队对Hudi的原理有较深理解,并建立相应的监控体系来跟踪提交、压缩、清理等后台作业的健康状况。
###
Apache Hudi通过将数据库的核心能力(事务、更新删除、索引)引入数据湖存储层,有效地弥合了传统大数据存储与实时业务需求之间的鸿沟。它不仅是存储格式的创新,更是一种新型的数据处理范式。作为数据处理和存储服务的关键组件,深入理解并合理实践Hudi,能够帮助企业构建更实时、更高效、更易维护的数据平台,从而在数据驱动的竞争中赢得先机。随着Hudi社区的持续活跃和功能的不断完善,它必将在未来的数据湖架构中扮演越来越重要的角色。
如若转载,请注明出处:http://www.ad-bdd.com/product/58.html
更新时间:2026-06-19 19:39:52