数据湖存储格式Hudi原理与实践
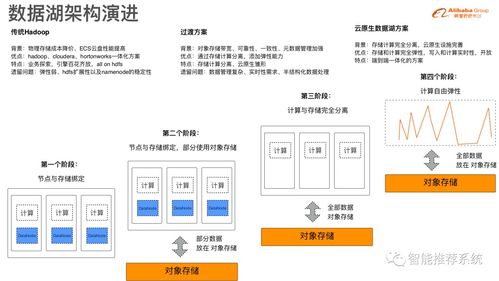
数据湖作为现代数据处理架构的关键组件,能够存储海量结构化和非结构化数据,并支持多种分析场景。Hudi(Hadoop Upserts Deletes and Incrementals)是专为数据湖设计的开源存储格式,通过提供高效的更新、删除和增量处理能力,解决了传统数据湖在实时数据处理中的痛点。
Hudi的核心原理
Hudi通过以下机制实现高效的数据管理:
- 数据组织与索引:Hudi将数据存储在基于时间线的文件集中,支持分区和全局索引,允许快速定位记录。
- 事务支持:通过ACID事务保证数据一致性,支持并发读写,避免数据冲突。
- 增量处理:Hudi维护变更日志,提供增量查询功能,仅处理新增或修改的数据,提升ETL效率。
- 存储格式优化:采用列式存储(如Parquet)和行式存储(如Avro)混合方式,平衡查询性能和写入速度。
Hudi的关键特性
- 更新与删除:Hudi支持主键级别的更新和删除操作,无需重写整个数据集,这在传统数据湖格式(如Parquet)中难以实现。
- 数据版本管理:通过时间线机制追踪数据变更历史,支持时间旅行查询,便于数据审计和回滚。
- 与计算引擎集成:Hudi与Apache Spark、Flink等流行计算引擎无缝集成,支持流式和批处理工作负载。
Hudi的实践应用
在实际数据处理和存储服务中,Hudi可用于构建实时数据湖方案:
- 实时数据摄取:从Kafka或其他流数据源摄入数据,使用Hudi进行增量更新,确保数据湖的实时性。
- 数据仓库加速:在数据湖上构建ODS(操作数据存储)层,通过Hudi的增量处理减少ETL延迟。
- 数据治理:利用Hudi的版本控制功能,实现数据血缘追踪和合规性管理。
总结
Hudi作为数据湖存储格式,通过其高效的更新、删除和增量处理能力,显著提升了数据处理和存储服务的灵活性和性能。结合具体业务场景,Hudi可以帮助企业构建低成本、高可用的实时数据平台,推动数据驱动决策。在实践中,建议根据数据规模、查询模式和延迟要求,合理配置Hudi的存储和索引策略,以最大化其效益。
如若转载,请注明出处:http://www.ad-bdd.com/product/36.html
更新时间:2025-11-28 06:20:13